Pandas
Pandas proporciona estructures de dades tabulades per a gestionar grans volums de dades de forma eficient. Permet ordenar, agrupar i obtenir estadístiques fàcilment.
Introducció
PENDET d’eliminar
DataFrames
Ja estàs familiaritzat amb Series, una estructura de dades unidimensional en pandas. Ara, coneixeràs una altra estructura de dades clau de pandas, que s’anomena DataFrame.
DataFrame és una taula amb columnes. De la mateixa manera que cada element d’un objecte Series està etiquetat amb un índex, cada fila d’un DataFrame està etiquetat amb un índex.
Aquí teniu un exemple d’un objecte DataFrame que emmagatzema informació sobre quatre estudiants:
| | | | |
||
| | | | |
| | | | |
| | | | |
| | | | |
Aquest DataFrame té tres columnes, és a dir First Name, Family Name, i Age.
Les quatre files estan etiquetades amb índexs 0, 1, 2, 3.
D’acord, però com el creem?
Creació d’un DataFrame: lectura d’un fitxer csv.
Guardar DataFrame a fitxer: escriptura de dades.
Hi ha un (diversos) mètodes anàlegs als que hem vist per guardar els resultats dels nostres dataFrames a fitxers; i comencen per to. Veiem com funciona el to_csv
El fitxer csv contindria:
,,
,,
,,
,,
,,El codi que usarem per llegir el fitxer i escriure’n un de nou.
# Llegim fitxer csv a dataframe.
: =
# Canviem dades de la primera estudiant.
=
=19
# Escrivim dataframe cap a fitxer csv a pandas
En principi s’haura de crear el nou fitxer amb el contingut; i el que es guarda és el següent (hem canviat cognom i edat de la primera estudiant).
El paràmetre index=False l’hem posat perquè no ens cal guardar l’index automàtic
del DataFrame.
,,
,,
,,
,,
,,Creació d’un DataFrame: lectura d’un fitxer csv d’Internet.
Ja hem explicat com n’és d’important descarregar un fitxer d’Internet via HTTP només si no el tenim descarregat
Ara veurem com carregar dataframes o sèries des de fitxers a Internet amb Pandas.
Mètode 1. Mètode read_csv i to_csv
El mètode read_csv agafa tant rutes de fitxers com url. Internament usa la llibreria requests per fer la descàrrega. És eficient, però no es permet tant de control com urllib3.
=
=
# Descarrega el fitxer (tant si ve del fitxer com si ve de URL)
=
# Guarda el fitxer només si s'ha descarregat de l'URL
La crida os.path.isfile(csv_file) descarregarà el fitxer només si no existeix al nostre directori.
Podeu provar que només descarrega el fitxer si no hi ha cap que es digui igual.
Mètode 2. Urllib3
Si voleu tenir més control sobre com es descarrega el fitxer i si hi ha hagut problemes de connectivitat, és millor usar urllib3.
Ja el vam estudiar a la sessió HTTP: https://xtec.dev/python/http/
: =
: =
=
=
# Descarrega el fitxer (tant si ve del fitxer com si ve de URL)
=
Informació útil del DataFrame: head(), info(), describe().
Primer, creem un exemple de frame de pandas amb informació sobre els cotxes: els seus noms, preus i si estaven trencats.
= : ,
: ,
:
}
=
Quan rebeu el vostre DataFrame per primera vegada, heu d’entendre la informació que hi ha.
Hi ha tres mètodes principals per fer-ho: .head(), .info(), .describe().
El mètode .head() de Pandas és un mètode útil per previsualitzar les primeres files d’un DataFrame. S’utilitza habitualment per obtenir una visió general ràpida de les dades i comprendre la seva estructura, els noms de les columnes i els valors reals del DataFrame.
Podeu passar el nombre de files per mostrar com a paràmetre n. Per defecte, només mostrareu 5 files.
# display the first 3 rows
0 25000 False
1 22000 True
2 35000 TrueEl mètode .info() de Pandas s’utilitza per mostrar metainformació sobre un DataFrame: tipus de dades de cada columna, el nombre de valors no nuls, ús de memòria i molt més.
< >
: 7 , 0 6
:
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 7 -
1 7 -
2 7 -
: , ,
: 247.0+ Quan cridem df.info(), obtenim la informació següent:
- <class ‘pandas.core.frame.DataFrame’>: indica que df és un DataFrame
- RangeIndex: 7 entries, 0 to 6: Mostra que el DataFrame té un índex d’interval de 0 a 6, que indica 7 files.
- Data columns (total 3 columns): Indica que el DataFrame té 3 columnes.
- Column: Llista els noms de les columnes (“Nom del cotxe”, “Preu” i “Està trencat”).
- Non-Null Count: mostra el nombre de valors no nuls per a cada columna. En el nostre exemple, no hi ha valors nuls.
- Dtype: especifica el tipus de dades de cada columna. ’Car Name’és de tipus ‘object’(generalment representa cadenes), ‘Price’ és de tipus ‘int64’(enter), i ‘Is Broken’ és de tipus bool. Tingueu en compte que, de vegades, les columnes es poden inferir de manera incorrecta, de manera que és possible que sigui necessari una inspecció i una conversió de tipus addicionals. Podeu definir els tipus de columnes canviant el dtype durant la lectura del fitxer. Alternativament, podeu utilitzar df.as_type() després de carregar el DataFrame per especificar els tipus correctes.
- memory usage: Mostra l’ús de memòria del DataFrame.
Si només us interessen els dtypes podeu usar l’atribut df.dtypes
El mètode .describe() de Pandas s’utilitza per generar un resum d’estadístiques per a columnes numèriques en un DataFrame.
Podeu obtenir la mitjana, recompte, std, primer, segon i tercer quantils i altres estadístiques de les dades.
7.000000
37428.571429
13709.572603
22000.000000
25% 27500.000000
50% 35000.000000
75% 45000.000000
60000.000000Prova de rendiment dels DataFrames.
Sempre és interessant realitzar proves d’estrés del rendiment que ofereixen els dataFrames, així valorem com fer-los més eficients.
Amb aquest codi podem mesurar el tamany i el temps que triga crear un gran dataFrame.
: = 2000000
=
=
= ,,,,]
=
=
=
Exercicis dataframes.
1.- Valors màxims
Baixa el fitxer de https://gitlab.com/xtec/bio/pandas/-/raw/main/data/persons.csv
Importa el fitxer amb pandas i obten el valor màxim de la columna Age.
2.- paràmetre index_col
De quina manera s’utilitza el paràmetre index_col de Pandas?
- Estableix la primera columna com a índex del DataFrame.
- Especifiqueu la columna d’índex quan llegiu un fitxer JSON.
- Establiu una columna d’índex personalitzada per al DataFrame.
- Especifiqueu la columna d’índex quan llegiu un fitxer CSV.
3.- Mètodes per visualitzar les dades
Relaciona els mètodes següents amb les seves descripcions:
- head()
- info()
- describe()
-
Genera un resum d’estadístiques per a columnes numèriques del DataFrame, com ara la mitjana, el recompte, la desviació estàndard i els quartils.
-
Proporciona una vista prèvia ràpida de les primeres files del DataFrame, ajudant a entendre la seva estructura i els noms de les columnes.
-
Mostra informació sobre el DataFrame, inclosos els tipus de dades de cada columna, el nombre de valors no nuls i l’ús de la memòria.
4.- Valors nuls
Baixa el fitxer de https://gitlab.com/xtec/bio/pandas/-/raw/main/data/persons.csv
Importa el fitxer amb pandas i digues quin és el nombre de valors no nuls de la columna Address.
5.- Filtra els noms de les files.
Des del mateix fitxer, mostra només les tres primeres files.
{% sol %}
2: 2;
3: 1-B, 2-C, 3-A;
1.-
=
=
=
El valor esperat és: 60
4.-
=
=
=
El valor esperat és: 281
5.-
...
{% endsol %}
Creació d’un DataFrame a partir d’altres estructures de dades
També és possible convertir altres estructures de dades, com ara diccionaris, llistes o matrius Numpy, a DataFrame. Heu de passar les dades al constructor DataFrame.
Per exemple, suposem que teniu una llista imbricada que conté informació sobre els estudiants i la volem convertir a DataFrame:
= ,
,
]
=
| | | | |
||
| | | | |
| | | | |
| | | | |
| | | | |
A més, podríem especificar un altre index en comptes del 0, 1, 2, … per defecte amb l’argument índex. Provem-ho:
=
=
= = ,
= )
Sortida:
| | | | |
||
| | | | |
| | | | |
| | | | |
| | | | |
En crear un DataFrame d’un diccionari imbricat, els noms d’índex i de columnes s’inferiran automàticament a partir de les claus del diccionari.
Mireu l’exemple:
# This is a nested dictionary representing the students table
= 200: ,
300: ,
400: },
: 200: ,
300: ,
400: },
: 200: 20,
300: 25,
400: 22}}
=
Sortida:
| | | | |
||
| | | | |
| | | | |
| | | | |
| | | | |
Shape –> Forma dels dataframes
Per comprovar quantes files i columnes té un Dataframe, pots accedir a l’atribut shape com feiem amb Numpy.
Conté una tupla amb dos valors, les dimensions al llarg dels dos eixos. Per exemple, en el nostre alumne DataFrame, hi ha quatre files i tres columnes:
# (4, 3)Selecció de primeres (head) i últimes (tail) files.
El DataFrame pot ser massa gran per imprimir-lo. En aquest cas, utilitza els mètodes head() i tail().
Imprimiran la primera o les últimes cinc files del DataFrame respectiu. Si voleu que es mostri un nombre diferent de files, només heu d’especificar-lo entre parèntesis.
Imprimim només les dues primeres files:
| | | | |
||
| | | | |
| | | | |
Selecció de columnes.
També podeu accedir a cadascuna de les columnes del DataFrame per separat posant el nom de la columna entre claudàtors després del nom del DataFrame. Tingueu en compte que cada columna del DataFrame és un objecte Series:
# 0 21
# 1 20
# 2 25
# 3 22
# Name: Age, dtype: int64Si necessiteu accedir a diverses columnes alhora, només heu de posar els seus noms en una llista. Mirem només la primera i l’última columnes. Tingueu en compte que la taula resultant és un nou objecte DataFrame:
| | | |
||
| | | |
| | | |
| | | |
| | | |
Tingueu en compte també que si voleu obtenir una sola columna d’un DataFrame com un altre objecte DataFrame enlloc d’un objecte Series, hauríeu de posar el nom de les columnes entre claudàtors dobles:
| | |
||
| | |
| | |
| | |
| | |
Organització de dades als DataFrames
Ja hem comentat quin tipus de dades es poden emmagatzemar en un DataFrame i com es poden crear.
Ara, anem a saber com podem modificar un DataFrame existent. En aquest tema, parlarem d’algunes operacions bàsiques, com ara canviar el nom, reordenar columnes o canviar l’índex.
Accés als eixos de DataFrame
En primer lloc, hem d’importar pandas i crear un DataFrame d’un diccionari:
= : ,
: ,
: ,
: ,
:
}
=
Aquí teniu la sortida:
+----+-----------+-------------------+--------+---------+--------------------+
| | | | | | |
|----+-----------+-------------------+--------+---------+--------------------|
| 0 | | | 4 | 0 | |
| 1 | | | 4 | 0 | |
| 2 | | | 2 | 2 | |
| 3 | | | 6 | 4 | |
+----+-----------+-------------------+--------+---------+--------------------+Podem canviar els índexs en tots dos DataFrames i Series. Els índexs poden utilitzar diferents tipus de dades, com ara cadenes, objectes Datetime, nombres flotants, valors booleans i altres.
Podeu veure l’índex de files a la primera columna de l’esquerra. Els noms de les columnes ( etiquetes ) es troben a la capçalera. Una altra manera de descriure la indexació és l’etiquetatge d’eixos.
Podeu veure dos eixos al nostre marc de dades, verticals (files) — axis 0 i horitzontal (columnes) — axis 1.
Fem una ullada als eixos del nostre DataFrame accedint a df.axes.
Això és el que obtindrem:
]El primer objecte de la llista és el mètode d’indexació per a files i el segon per a columnes.
La manera predeterminada d’indexar les dades que contenen n files és utilitzant un interval d’enters 0, 1, 2, 3,…, n−1.
Aquest índex reflecteix les posicions dels elements. Com podeu veure més amunt, el nostre DataFrame utilitza només aquest tipus d’indexació de files (interval d’enters): la primera fila té el 0 índex, l’última fila té índex 3.
Comprovem la sortida del mètode df.info():
< >
: 4 , 0 3
:
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 4 -
1 4 -
2 4 -
3 4 -
4 4 -
: ,
: 288.0+ Com podeu veure, la primera línia descriu la classe d’objecte ( DataFrame), després el tipus de dades per a la indexació i, a continuació, hi ha una llista de columnes que conté índexs de columnes posicionals, etiquetes de columnes, Non-null Count (el nombre de files no buides) i dtype (un tipus de dades, es detecta automàticament com a object per Pandas).
L’objecte d’índex de fila s’emmagatzema df.index
Podem veure l’índex actual cridant l’atribut corresponent al marc de dades:
Com que no hi ha etiquetes de fila, l’atribut retornarà un interval d’enters. Podeu aconseguir el mateix resultat utilitzant df.axes[0].
Consell: .info() també us ofereix índexs posicionals. A més de la indexació posicional, de vegades és útil utilitzar etiquetes personalitzades.
Per veure les etiquetes de columna d’a DataFrame, utilitzar df.columns:
Configurar, canviar i restablir un índex
Una manera de canviar els noms de les columnes és assignar un nou valor a la columns atribut. El nou valor ha de tenir la mateixa longitud que el nombre de columnes.
Canviem el valor d’algunes columnes assignant una llista de nous valors a l’atribut columns:
=
Aquí teniu la sortida:
+----+-----------+-------------------+--------+--------+--------+
| | | | | | |
|----+-----------+-------------------+--------+--------+--------|
| 0 | | | 4 | 0 | |
| 1 | | | 4 | 0 | |
| 2 | | | 2 | 2 | |
| 3 | | | 6 | 4 | |
+----+-----------+-------------------+--------+--------+--------+Com podeu veure, les columnes ara tenen noms diferents. Podem assignar una nova llista d’etiquetes al index atribut:
=
Així serà la taula:
| | | | | | |
||
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
També podeu utilitzar qualsevol columna com a índex. Indexem les nostres dades pel nom. Ho podem fer amb el mètode set_index().
Així que podem assignar un nou DataFrame objecte al nostre df variable o utilitzeu un argument opcional inplace=True.
Aquesta funció alterarà totalment el Dataframe existent (internament es crearà un nou Dataframe i s’esborrarà l’anterior).
Tornem al nostre DataFrame i restablir el seu índex.
# is equivalent to df = df.set_index('name')
Aquí teniu la sortida:
| | | | | |
||
| | | | | |
||
| | | | | |
| | | | | |
| | | | | |
| | | | | |
Ara, la indexació es basa en la columna name. Si mirem l’atribut index que s’utilitza ara df.index, podem veure que va canviar de rang a la llista de noms:
Consell: Només l’objecte DataFrames té el mètode .set_index().
Podem tornar a restablir la columna d’índex al valor predeterminat (interval sencer) fent servir reset_index().
Com s’ha esmentat anteriorment, utilitzeu inplace=True per guardar els canvis:
Sortida:
| | | | | | |
||
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
Un cop hem restablert l’índex, la columna name passa a ser la primera. Si voleu reindexar les vostres dades i suprimir els índexs existents, feu servir drop=True.
Canviar el nom de columnes
També podeu utilitzar el mètode .rename() per canviar el nom de les columnes. Només cal passar un diccionari amb noms de columnes antics com a claus i noms de columnes noves com a valors:
Aquí teniu la sortida:
| | | | | | |
||
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
Com podeu veure, tot és molt còmode. No cal esmentar totes les columnes si només volem canviar el nom d’algunes d’elles.
També pots utilitzar .rename() per canviar els noms índexs: només cal passar el index = {…} argument en lloc de columns={…}.
Sistemes de coordenades Dataframes: .iloc i .loc
Podem accedir a una peça d’informació emmagatzemada en una fila o una columna concreta en lloc de treballar amb tota la informació del Dataframe.
Ho fem amb indexació i podem seleccionar un subconjunt particular de a DataFrame o a Series per treballar-hi.
En un dataframe, el sistema de coordenades, comença per 0, i la coordenada s’indica primera la fila i després la columna.
Regla nemotècnica (enfonsar-se i nedar)
-
Primer et tires de cap a la posició de la fila que vols.
-
Després, vas nedant fins la columna que t’interessa.

Abans de començar, importem pandas (abreujat com pd) i creem un DataFrame d’un diccionari:
= : ,
: ,
: , ],
: ,
:
}
=
Aquí teniu la sortida:
pandas ofereix dues funcions addicionals per seleccionar un subconjunt de files i columnes: .loc i .iloc
Tingueu en compte que les dues característiques no són mètodes: són propietats de Python i, per això, utilitzen claudàtors. Primer, recordeu que la seva sintaxi bàsica és similar:
.
..iloc
Comencem amb .loc; el més habitual.
Pot gestionar índexs basats en nombres enters com a etiquetes, però per a més claredat, crearem i anomenarem un índex de text:
=
=
Sortida:
.loc pot prendre:
- una sola etiqueta de fila;
- una llista d’etiquetes de files;
- un tros d’etiquetes de fila;
- un resultat de declaracions condicionals (una matriu booleana)
També podríem passar columnes com a segon argument d’una manera similar: una sola etiqueta, una llista o una porció.
Si passem un sol argument, pandas tornarà a Series:
També podeu seleccionar una sola cel·la:
Sortida:
Com podeu veure, hem retornat un valor de cel·la. En aquest cas, és del tipus String.
Per passar una llista d’etiquetes, hem de fer el següent:
Obtenim les files amb el primer i el quart índex:
Afegim una llista de columnes d’etiquetes:
Sortida:
Tingueu en compte que la primera llista dins del loc els claudàtors defineixen la selecció de fila mentre que la segona llista defineix la selecció de columnes.
Aquí ve una porció d’etiquetes de fila:
Sortida:
Igual que abans, podem introduir una condició (amb una porció de columna):
Sortida:
El primer argument aquí pren una fila mentre la columna d’aniversari s’estableix a 12.05.1979. El segon argument pren columnes de last_name a birthday amb un pas de 2.
És a dir, triga cada segona columna, començant per la primera seleccionada.
No dubteu a triar qualsevol combinació de valors, llistes i seccions individuals.
=
Sortida:
Exercici loc.
Com podem obtenir el nom de la persona amb la alçada mínima ?
{% sol %}
# Pas 1. Obtenir el mínim
=
# Pas 2. Obtenir el nom del mínim, sabent el mínim
= {% endsol %}
.iloc
La sintaxi bàsica d’iloc és la mateixa que a loc, però aquesta se centra en els índexs enters ordinals; aquí no podem utilitzar condicionals.
Per tant, torneu a l’inici DataFrame restablint i deixant anar l’índex d’etiquetes; ja no en necessitem:
Sortida:
Al principi, seleccionem el valor de la primera fila i columna:
Retorna la cel·la:
També podem seleccionar quatre cel·les internes:
Sortida:
1 @
2 @No t’oblidis del pas! Per definir un pas k dins d’un interval de fila [x,y], utilitzeu la sintaxi següent:
df.iloc[x:y:k, :]
Per exemple, podem enumerar cada segona fila (a partir de zero) amb aquesta línia de codi:
Sortida:
Genial, no? Aquesta tècnica sembla senzilla si ja esteu familiaritzat amb les llistes de Python.
Tingues en compte que .iloc pren una posició entera. Vol dir que si no tenim una numeració de línia d’extrem a extrem, prendrà les posicions de la fila.
Així que si tenim una indexació fantàstica com aquesta:
df.iloc[0] encara seleccionarà la primera fila (amb un índex de 10):
I df.loc[0]seleccionarà la segona fila (amb un índex de 0):
Ús .loc i .iloc quan es vol canviar una part DataFrame.
En resum, anem a veure les principals diferències entre .loci .iloc en una taula:
| .loc | .iloc | |
|---|---|---|
| Selecció de fila condicional | Sí | No |
| Pren files com | Noms d’índex | Posició entera de l’índex |
| Pren les columnes com a | Noms de columnes | Posició entera de la columna |
Modificació d’un DataFrame amb loc & iloc
Tots dos mètodes no només són una manera convenient de seleccionar una part d’a DataFrame, però també ajuden a modificar una part d’a DataFrame només amb una línia de codi.
Imaginem una situació: per desar dades personals en un servidor, els usuaris us han d’enviar un Acord de tractament de dades (DPA).
Suposem que no has rebut el DPA de Jane i John Doe.
Actualitzem les nostres dades:
= Això és el que obtindrem:
Selecció condicional
De vegades, és possible que vulguem accedir a una informació emmagatzemada en una fila o una columna concreta en lloc de treballar amb un DataFrame sencer.
La bona notícia és que Pandas ens permet fer-ho. S’anomena indexació ; podem seleccionar un subconjunt particular de a DataFrame o a Series per treballar-hi.
Selecció
Abans de començar, importem pandas(abreujat com pd) i creeu un DataFrame a partir d’un diccionari:
= : ,
: ,
: ,
: ,
:
}
=
Sortida:
+----+--------------+-------------+--------------------+------------+----------+
| | | | | | |
|----+--------------+-------------+--------------------+------------+----------|
| 0 | | | @ | 29.09.1958 | 1.75 |
| 1 | | | @ | 17.02.1963 | 1.98 |
| 2 | | | @ | 15.03.1978 | 1.64 |
| 3 | | | @ | 12.05.1979 | 1.8 |
+----+--------------+-------------+--------------------+------------+----------+Podem seleccionar qualsevol subconjunt del DataFrame, per exemple, una sola columna:
Sortida:
Ara tenim un Pandas sèrie amb correus electrònics.
També és possible utilitzar-lo df.email. S’anomena sintaxi de punts.
El podem utilitzar per a noms de columnes sense espais.
També podem seleccionar una llista de columnes. Una llista de Python requereix claudàtors addicionals:
Sortida:
+----+--------------+-------------+
| | | |
|----+--------------+-------------|
| 0 | | |
| 1 | | |
| 2 | | |
| 3 | | |
+----+--------------+-------------+Ara tenim un nou DataFrame, format per aquestes dues columnes. Aquesta ordre sempre retorna un DataFrame, de manera que, fins i tot si seleccioneu una llista que consta d’una columna, tornareu un DataFrame:
Sortida:
+----+-------------+
| | |
|----+-------------|
| 0 | |
| 1 | |
| 2 | |
| 3 | |
+----+-------------+Condicionals
Si hem d’introduir una condició per refinar la nostra elecció, podem incloure-la entre claudàtors:
Sortida:
+----+--------------+-------------+--------------------+------------+----------+
| | | | | | |
|----+--------------+-------------+--------------------+------------+----------|
| 0 | | | @ | 29.09.1958 | 1.75 |
| 2 | | | @ | 15.03.1978 | 1.64 |
+----+--------------+-------------+--------------------+------------+----------+Com a resultat, hem retornat totes les columnes i files on height el valor és inferior a 1,8.
Tingueu en compte que és possible utilitzar claudàtors dins d’aquesta declaració, per exemple, df[df[‘height’] < 1.8], però no cal que ho fem aquí, ja que el nom de la columna no conté espais en blanc.
Si necessitem combinar diverses condicions, utilitzem els següents operadors booleans:
- & per “i”
- | (línia vertical) per “o”
- ~ per “no”
-
, <, >=, <=, ==, !=per comparar declaracions.
Si us plau, no us oblideu del parèntesi:
Sortida:
+----+--------------+-------------+-------------------+------------+----------+
| | | | | | |
|----+--------------+-------------+-------------------+------------+----------|
| 1 | | | @ | 17.02.1963 | 1.98 |
+----+--------------+-------------+-------------------+------------+----------+Com a resultat, vam tornar les files que coincideixen amb la nostra condició preestablerta: “el primer nom és Michael, l’aniversari és el 17.02.1963”.
Un exemple més amb una condició una mica més complexa. Definim el primer nom com Michael o John, una alçada igual o superior a 1,8. El cognom no hauria de ser Jordan:
&
& ])Sortida:
+----+--------------+-------------+-------------------+------------+----------+
| | | | | | |
|----+--------------+-------------+-------------------+------------+----------|
| 3 | | | @ | 12.05.1979 | 1.8 |
+----+--------------+-------------+-------------------+------------+----------+Tingueu en compte que no fem servir el caràcter de salt de línia , ja que totes les línies noves es posen dins dels claudàtors.
Si volem fer exclusiu el nostre filtratge , és a dir, seleccionar-ho tot excepte els paràmetres indicats, podem afegir un caràcter de tilde ~i parèntesis addicional:
&
& )]Sortida:
+----+--------------+-------------+--------------------+------------+----------+
| | | | | | |
|----+--------------+-------------+--------------------+------------+----------|
| 1 | | | @ | 17.02.1963 | 1.98 |
+----+--------------+-------------+--------------------+------------+----------+Filtrem amb queries.
Les versions de Pandas 1.3 i posteriors permeten filtrar amb una altra sintaxi, semblant al SQL.
Aquesta consulta:
És equivalent a:
Camps categorical. Millora del rendiment dels strings.
Quan ens trobem amb un camp que pot tenir uns pocs valors, que es podrien representar en una llista de selecció (el select d’html) ens interessa crear un camp categorical.
Exemples de camps categòrics poden ser: gènere, grup sanguini, estat civil, continent del món, Sí/No/NoContesta, etc…
Per crear un categòric de gènere ho podem fer de dues maneres.
Mètode 1. Amb el constructor pd.Categorical:
Si ja sabem tots els possibles valors categòrics del dataset, com pot ser el camp gender, el que ofereix millor rendiment és aquest constructor.
= Mètode 2. Amb la funció astype:
Si volem transformar una columna d’strings (dtype object per defecte) a categorical hem d’usar els mètodes astype; suposem el següent exemple:
: =
=
=
Després d’executar aquest codi, veuràs que la columna continent ha canviat el seu tipus de dades a category, el que permet optimitzar memòria i millorar el rendiment en operacions com el recompte d’ocurrències.
Una variant d’aquest mètode és crear camps categòrics quan llegim el dataframe o serie usant el mètode dtype:
= =)
A nivell de rendiment, aquest mètode no és tant eficient com el constructor, perquè pandas ha de deduïr un per un de quin tipus és cada valor. Però per a programar és més còmode.
Recompte d’ocurrències de cada valor columna.
Per analitzar de forma ràpida grans volums de dades ens serà molt útil comptar les ocurrències de cada valor en cada columna, sobretot si són categòrics o numèrics discrets (pocs possibles números)
Funcions com unique, value_counts, i altres que poden ajudar a entendre millor els valors de les columnes del dataframe drinks.
Seguim amb l’exemple de les begudes:
=
=
= unique
El mètode unique() et permet veure tots els valors únics d’una columna. Això és útil si vols saber quins són els valors diferents que existeixen en una columna.
Exemple: Quins continents únics tenim?
# Quins continents únics tenim?
Sortida:
['Asia', 'Europe', 'Africa', 'North America', 'South America', 'Oceania']value_counts
El mètode value_counts() compta la quantitat de vegades que apareix cada valor d’una columna. La estructura que et retorna és una Serie.
Aquest és un dels mètodes més útils per explorar dades, ja que et dóna una idea de com es distribueixen els valors.
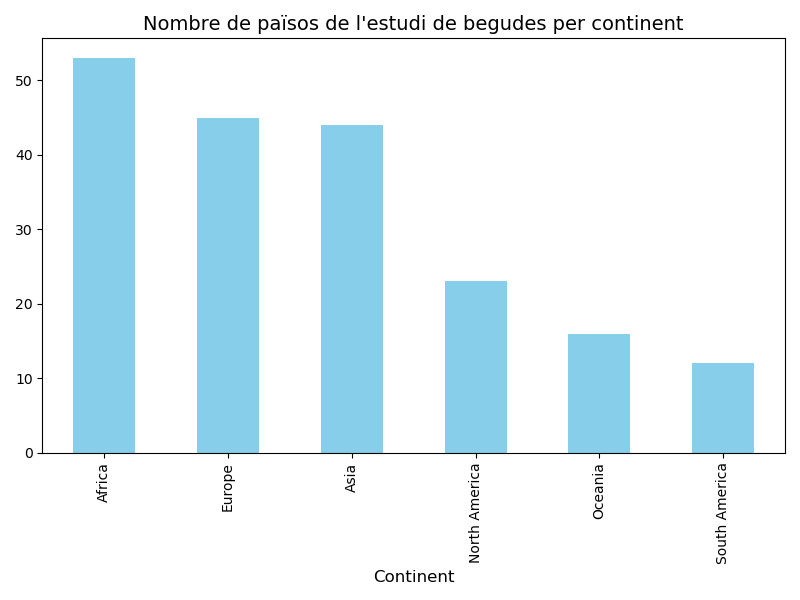
Exemple: Comptem quants països hi ha per cada continent
Sortida:
Africa 53
Europe 45
Asia 44
North America 23
South America 12
Oceania 16
Name: continent, dtype: int64Això ens diu quants països corresponen a cada continent. Si hi hagués algun valor no vàlid o missings (com nan), no es comptarien per defecte, però pots incloure’ls utilitzant dropna=False:
Això inclouria la comptabilitat de valors NaN (si n’hi haguessin).
sort_values
Una vegada tens els valors amb value_counts(), pots ordenar-los utilitzant sort_values(). Això és útil si vols veure els valors en ordre ascendent o descendent de freqüència.
Exemple:
# Ordenar els continents per nombre de països de menor a major
Sortida possible:
South America 12
Oceania 16
North America 23
Asia 44
Europe 45
Africa 53
Name: continent, dtype: int64Això t’ajuda a veure ràpidament quins continents tenen menys països representats en el conjunt de dades.
Aquests mètodes funcionen igual de bé amb qualsevol altra columna. Per exemple, podries veure quins valors diferents hi ha a la columna beer_servings, i quants països tenen un nombre específic de beer_servings:
# Quins valors únics hi ha a beer_servings?
# Comptem quantes vegades apareix cada valor de beer_servings
replace, remplaçar valors en columnes:
Com que replace() és molt útil per modificar valors específics, pots utilitzar-lo per canviar el nom d’equips o qualsevol valor en el dataframe.
Exemple:
# Reemplacem el nom d'alguns continents (fictici exemple)
=
Anem a provar un altre exemple, suposem que en comptes d’equips amb nom ‘A’, ‘B’ i ‘C’ els volem reemplaçar per altres noms. Endavant!
= : })
=
Matplotlib i pandas.
Matplotlib permet crear gràfics amb Series i DataFrames molt fàcilment.
En aquest punt veurem 2 exemples senzills, i a la secció d’estadística veurem uns quants exemples més.
Gràfic de barres. Recompte d’ocurrències d’una variable.
Agafem l’exemple de les begudes, per a fer un gràfic de barres del número de països de cada continent (una Serie) que s’han inscrit a l’estudi.
=
=
=
=
Gràfic de línies. Evolució.
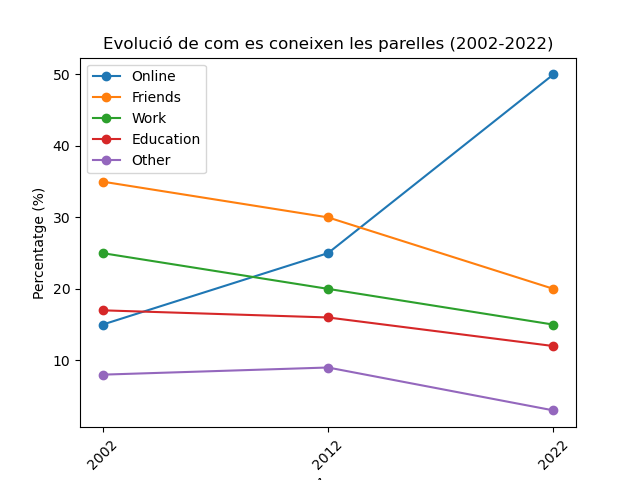
Agafem les dades d’un estudi d’Stanford sobre com es coneixen les parelles a través dels anys i mostrem un gràfic de com ha evolucionat als anys 2002, 2012 i 2022.
# Basat en l'estudi de
# https://data.stanford.edu/hcmst2017
= : ,
: ,
: ,
: ,
: ,
:
}
=
# Bucle per generar les línies del gràfic
# Ometem la primera columna 'Year'
# Per algun motiu que desconeixem, estem obligats a convertir Year.
=
# plt.tight_layout()
Exercicis: estudi oestoporosi.
Importa aquest estudi sobre la osteoporosis que es va fer a divereses pacients
Tingueu en compte que si no el tenim el descarregui i si ja el tenim només el llegeixi.
Article i fitxer originals:
Què demanem ?
- Fes que el dataframe només contingui les següents columnes:
-
edad (en anys).
-
imc (índex de massa corporal)
-
bua (resultat de l’exploració densitomètrica)
-
classific (normal / osteopenia / osteoporosi)
-
menarqui (edat primera menstruació, en anys)
-
edat_menop (edat inici menopausa, en anys)
-
menop → menopausa (sí, no)
-
tipus de menopausa
-
Obtén els dtypes i el tamany en memòria, per veure si s’ha carregat bé. → info
-
Mostra les 10 primeres files.
-
Obtén la mitjana de l’imc i de la edat de les pacients. → describe
-
Mostra les dades de la pacient més jove de l’estudi
-
Mira si hi ha valors NaN en alguna columna. En quines?
-
Obtén la classificació de les pacients que van des de la posició 100 a la 199. → loc, iloc
-
Obtén la edat i l’imc de les pacients que van des de la posició 50 al 99. → loc, iloc
-
Transforma dos camp cap al tipus categorical.
-
Fes el recompte d’ocurrències d’una variable object i una de categorical; ordenades.
-
Guarda els canvis en un nou fitxer.
Consideracions importants!
-
Assegura’t que al carregar el dataFrame s’agafen els tipus adequats, usant el atribut
dtypedins de la funcióread_csv. -
Ves en compte amb l’IMC i altres tipus de dades, que separen el decimal amb la
,i no pas amb el.com espera pandas per defecte. Ho has de convertir correctament.
{% sol %}
=
=
=
# Descarrega el fitxer si no existeix
= : ,
: ,
: ,
: ,
: ,
: ,
:
})
# 1. Filtrar el dataframe per les columnes requerides
=
# 2. Obtenir info del dataframe
# 3. Mostrar les 10 primeres files
# 4. Obtenir la mitjana de l'IMC i de l'edat de les pacients
# 5. Mostrar les dades de la pacient més jove
# Trobar l'edat mínima
=
# Filtrar el DataFrame per mostrar les dades de la pacient més jove
=
# Solució alternativa no vista.
# print(df_oestop.loc[df_oestop['edad'].idxmin()])
# 6. Comprovar si hi ha valors NaN en alguna columna
# Solució que no hem vist.
# print(df_oestop.isna().sum())
# 7. Classificació de les pacients de la posició 100 a 199
# 8. Edat i IMC de les pacients de la posició 50 al 99
# 9. Transformar dos camps cap al tipus categorical
=
=
# 10. Recompte d’ocurrències
# 11: guardar el nou fitxer si es vol
=
Altres exemples:
# Dades de pacients entre 60 i 70 anys
=
# Filtrar pacients amb osteoporosi
=
{% endsol %}
14.- Crea un gràfic del recompte de pacients del camp clasific: quants tenen estat normal, oestoporosi i oestopenia.
{% sol %}
Agafa el mateix codi que has usat per crear el dataframe i afegeix aquestes línies per a generar el gràfic.
# Crear el gràfic de barres
{% endsol %}
Exercicis reforç: loc & iloc i selecció condicional.
Donat aquest codi que crea dades generals sobre alumnes, crea un dataframe i realitza les següents operacions.
=
=
=
=
: = : ,
: ,
: ,
: }
= =,
=
)Operacions.
- L’index ha de ser el nom de l’alumne. Apart de ser índex també ha de ser un camp.
- Mostra la mitjana de notes de tots els alumnes.
- Ordena els alumnes alfabèticament.
- Mostra tota la info d’un alumne, a partir del seu nom.
- Mostra les notes dels 3 alumnes que tenen una nota més alta.
- Mostra els alumnes que tenen una nota superior o igual a 7.
- Espai per a que creis una consultes i la seva solució, a partir de les noves consultes que has creat.
- Crea un camp de gènere categòric.
{% sol %}
Ja ho hem fet al crear el dataframe. Si no ho haguessim fet hauriem d’usar el mètode set_index
=
=
=
=
: = : ,
: ,
: ,
: }
#1. L'index ha de ser el nom els estudiants.
= =,
=
)
#2. Mostra la mitjana de notes de tots els alumnes.
#3. Ordena els alumnes alfabèticament.
=
# 4. Mostra tota la info d'un alumne, a partir del seu nom.
# Si volguessim info sobre només un atribut d'un alumne.
# students_frame.loc[["Mary"],"grade"]
# 5. Mostra les notes dels 3 alumnes que tenen una nota més alta.
#Possible solució - ordenar els alumnes per nota i mostrar els 3 primers.
=
# 6. Alumnes amb nota superior o igual a 7
=
# 7. Consulta que tu vulguis. Exemples.
# Consulta les notes de la Mary.
# Mostra el camp index i la nota dels alumnes, ordenats alfabèticament.
=
# 8. Crea un camp de gènere categòric.
# Si no ho haguessim fet en la creació, ho fariem així:
{% endsol %}
Agrupació i agregació, molt important per a l’anàlisi de dades
En realitzar l’agregació, transformem les nostres dades en informació.
Per exemple, ens pot interessar agrupar tots els pacients per grups d’edat, o per gènere; per a fer un recompte de quants n’hi ha de cada (pex 11 dones i 14 homes).
També, per fer altres funcions d’agregació un cop agrupades; com la mitjana del sou d’homes i dones.
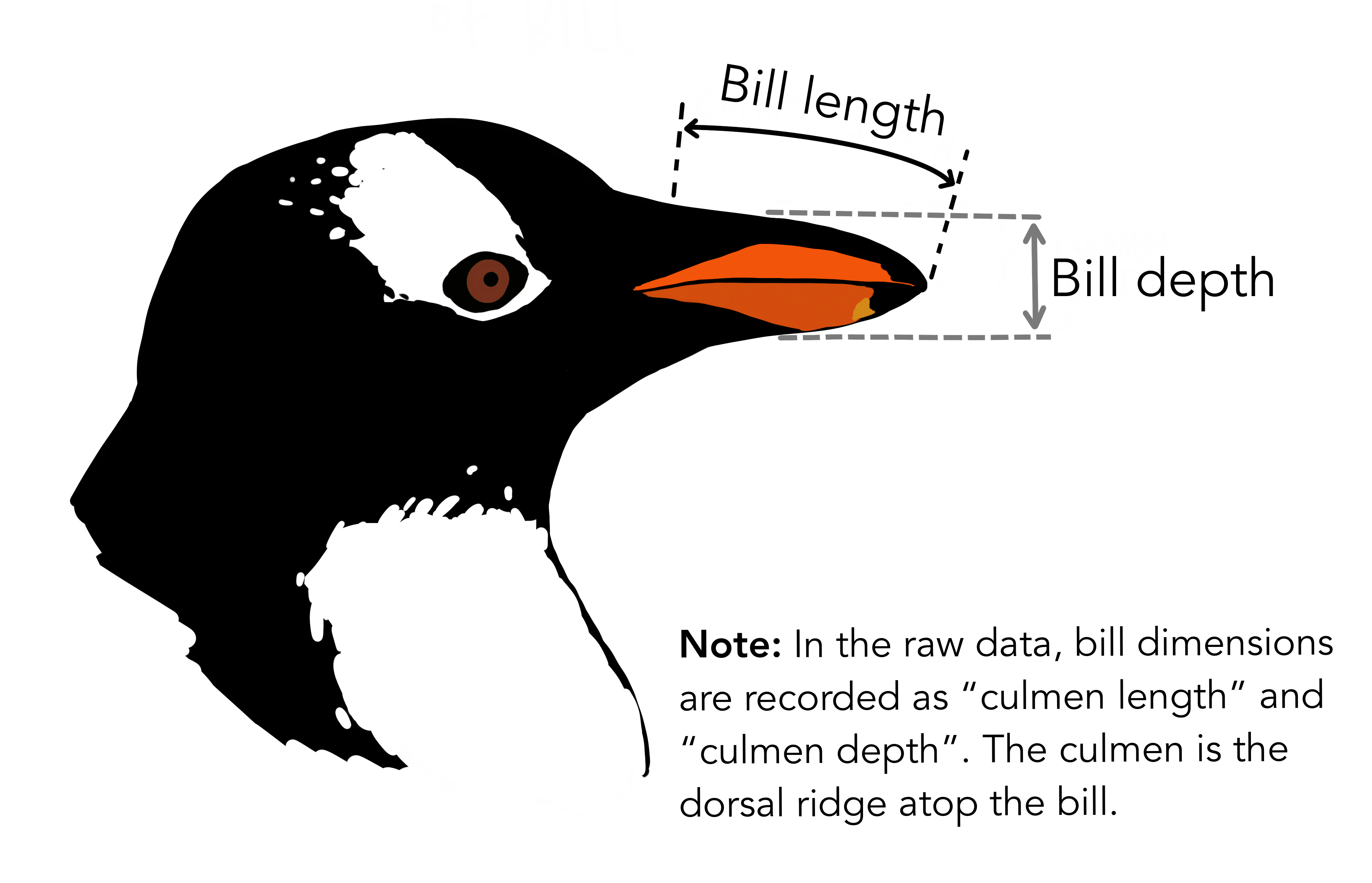
Exemple: Conjunt de Dades dels Pingüins de Palmer
En aquest tema, utilitzarem el conjunt de dades dels Pingüins de Palmer com a exemple.
Pots importar-lo des de GitHub amb les següents línies:
: =
: =
= El títol de cada columna parla per si mateix:
Sortida:
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
0 Adelie Torgersen 39.1 18.7 181.0 3750.0 MALE
1 Adelie Torgersen 39.5 17.4 186.0 3800.0 FEMALE
2 Adelie Torgersen 40.3 18.0 195.0 3250.0 FEMALEObservació: bill_length_mm i bill_depth_mm són la longitud i profunditat del bec (on mengen) i flipper_lenght_mm la longitud de les aletes.
DataFrame.aggregate
.aggregate() és un mètode de pandas DataFrame i Series que s’utilitza per a l’agregació de dades. Es pot utilitzar per a una o moltes funcions al llarg de qualsevol eix. Per estalviar temps per a coses realment importants (com el Machine Learning o Netflix), potser voldràs utilitzar la versió més curta del mètode — .agg(). Vegem els següents exemples.
Suposem que volem trobar el valor mitjà de la massa corporal del pingüí. Ho pots fer aplicant el mètode .agg() a la sèrie desitjada:
Sortida:
4050.0Quatre quilos de tendresa antàrtica en blanc i negre!
Consell: Pots passar una funció, el nom de la funció (com a cadena de text), una llista de funcions (o els seus noms) o un diccionari a .agg().
Per exemple, 'unique' en df.body_mass_g.agg('unique') obtindrà els elements únics de la columna body_mass_g, 'nunique' comptarà els elements únics en la columna especificada, i 'sum' en df.body_mass_g.agg('sum') produirà la suma dels valors de body_mass_g.
A més, pots passar una funció així (aquí passem la funció incorporada de Python sum(), però es pot passar qualsevol funció que gestioni un DataFrame):
Una altra manera de fer-ho és cridant al mètode .median() de la sèrie:
La diferència és que utilitzant el mètode .agg(), també podem aplicar diverses funcions d’agregació a diferents columnes. Per exemple, trobem el bec més curt i el mitjà del pingüí, així com les aletes més llargues i les mitjanes.
Per fer això, hem de cridar la funció agg() i crear un diccionari de Python utilitzant les columnes com a claus del diccionari. A més, necessitem posar les funcions d’agregació en llistes:
:
})Sortida:
bill_length_mm flipper_length_mm
min 32.10000 NaN
mean 43.92193 200.915205
max NaN 231.000000Recompte de valors NaN.
Consell: La funció retorna NaN per als valors que no hem especificat.
També és possible agregar les dades amb les teves pròpies funcions. L’exemple de la funció a continuació retorna el nombre de valors perduts. Si el conjunt no conté aquests valors, posa 0 (per defecte):
return
return - Fem-ho servir en el nostre DataFrame:
Sortida:
species 0
island 0
bill_length_mm 2
bill_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 11
dtype: int64Si necessites passar un paràmetre a la funció agg(), simplement enumera els seus noms i valors separats per una coma després del nom de la funció:
Sortida:
species Hurray!
island Hurray!
bill_length_mm 2
bill_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 11
dtype: objectConsell: Si utilitzes funcions no pandas (NumPy o les teves pròpies) — no posis els seus noms entre cometes.
Si vols trobar el valor més gran d’un conjunt específic de característiques per a cada pingüí (suposem que volem veure el valor més gran de 3 característiques — bill_length_mm, bill_depth_mm, i flipper_length_mm), aplica .agg() sobre les columnes establint l’argument axis a ‘columns’.
També podem trucar al mètode .agg() per treballar amb un dataframe que només conté valors numèrics. Utilitzem la funció incorporada de Python max(). Resulta en una sèrie de pandas:
=)Sortida:
0 181.0
1 186.0
2 195.0
3 NaN
4 193.0
...
339 NaN
340 215.0
341 222.0
342 212.0
343 213.0
Length: 344, dtype: float64DataFrame.groupby
Podem obtenir una sortida estadística de diferents columnes amb l’agregació, però per entendre les dades en profunditat, necessitem tenir una mirada més propera a diverses parts i combinacions de columnes. Per a aquest propòsit, podem utilitzar groupby(). És una eina molt senzilla, especialment per a aquells que ja estan familiaritzats amb SQL.
Ara comprovem la longitud mitjana del bec per a femelles i mascles. Agrupa tots els pingüins pel seu sexe i agrega’ls amb una línia:
Sortida:
bill_length_mm
sex
FEMALE 42.8
MALE 46.8El df.groupby(['sex']) solament retorna alguna cosa com <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002A1E7BE8358>. Això és perquè només és un objecte en memòria amb valors dividits per a grups indicats. L’intèrpret no sap què mostrar tret que ho especifiquis directament amb .agg().
Com has notat, la columna “sex” conté 11 valors perduts (alguns pingüins han preferit no compartir el seu gènere). Per incloure’ls en la nostra agrupació, estableix l’argument dropna de groupby a False (es requereix pandas 1.1 o superior):
Sortida:
bill_length_mm
sex
FEMALE 42.8
MALE 46.8
NaN 42.0Ara podem assumir que els pingüins de sexe desconegut són majoritàriament femelles.
A continuació, suposem que la dieta del pingüí varia per illa, i afecta la longitud del bec. Per comprovar si té sentit o no, agrupem els nostres amics antàrtics per illa i sexe. Tingues en compte que quan necessitem passar diversos arguments, hem de passar una llista:
Sortida:
bill_length_mm
island sex
Biscoe FEMALE 44.9
MALE 48.5
Dream FEMALE 42.5
MALE 49.1
Torgersen FEMALE 37.6
MALE 41.1L’ordre dels arguments en la llista d’arguments de .groupby() determina l’ordre d’agrupació. Primer vénen els grups, després els subgrups, els subgrups dels subgrups, i així successivament.
Consell: Com has vist fins ara, groupby farà que les etiquetes de grup que li passes es converteixin en columnes d’índex — el paràmetre as_index és responsable d’això i està configurat a True per defecte. Per al nostre últim exemple, si truquem a .index.names, podem veure que tenim 2 índexs — ‘island’ i ‘sex’:
..La sortida tindrà aquest aspecte: FrozenList(['island', 'sex'])
En cas que vulguis evitar establir l’índex (els índexs) a les etiquetes de grup passades a .groupby(), has d’establir as_index a False:
Exercicis agrupació dades dels pingüins.
Des del mateix dataset dels pingüins de Palmer, realitza les segúents operacions.
1.- Retorna el nom de les espècies de pingüins agrupades per illes.
Resultat esperat:
species
island
Biscoe [Gentoo, Adelie]
Dream [Chinstrap]
Torgersen [Adelie]2.- Compta el número de pingüins que hi ha a cada illa.
Resultat esperat:
island species
0 Biscoe 168
1 Dream 124
2 Torgersen 523.- The meanest penguin Mostra el pes mitja en quilograms (mean). Arrodoneix la resposta a 2 decimals.
4.- Compta el número de pingüins femella i mascle dins del dataset.
Resultat esperat aproximat:
species
sex
FEMALE X
MALE Y5.- Cadena de pingüins en cada illa Mostra la suma de la longitud de les aletes de cada espècie de pingüí de cada illa, així sabrem quanta distancia abarquen tots els pingüins junts.
flipper_length_mm
island species
Biscoe Adelie 203.0
Gentoo 1962.0
Dream Adelie 559.0
Chinstrap 398.0
Torgersen Adelie 936.0{% sol %}
Recorda com carregar el fitxer:
= )
#print(df.describe())
= / 1000
= {% endsol %}
Exemple 2 - Visites eCommerce.
Ja vam veure una funció d’agrupació senzilla i potent: el value_counts, per fer el recompte d’ocurrències dels possibles valors d’un camp.
Però a vegades no és suficient, ens interessa filar més prim. Per exemple, ens interessa sumar valors per gurps d’una categoria concreta, calcular-ne la mitjana, màxim…
agrupació (groupby).
Imaginem-nos que hem muntat un e-Commerce (una botiga digital) i tenim dades de 4 usuaris amb:
- la data en què van entrar
- el nom
- el temps de sessió en minuts (quant de temps van estar a la botiga)
- el que van gastar quan van comprar.
Els tenim organitzats en aquest dataframe:
= : ,
: ,
: ,
:
})
Ja sabem com fer la suma del temps de sessió de tots els usuaris, de fer el recompte d’usuaris per dia i altres.
Però com aconseguim saber el temps de sessió i despesa total de cada dia ?
Molt fàcil: agrupem les dades pel camp dia i fem la funció d’agregació sum
=
També podem mostrar la despesa total de cada usuari en tots els dies.
Fixeu-vos com n’és d’interessant fer un gràfic d’aquesta informació.
agregació de files calculades (agg).
Una altra funcionalitat molt potent és crear un dataframe amb diverses dades agrupades de les despeses de cada dia, o per nom.
= =,
=)
total media
dia
2023-02-22 131.01 32.7525
2023-02-23 114.78 28.6950Pregunta: Com ho farem per saber el total, la mitjana i el màxim que ha gastat cada usuari ?
Resposta:
= =,
=,
=)
total mitjana max_dia
nom
Carla 91.95 45.975 56.78
Cristina 23.19 11.595 14.24
Josep 29.00 29.000 29.00
Juan 34.99 17.495 20.00
Pepe 65.66 32.830 39.99Conclusions agg i groupby
En aquest tema, has après a:
- Calcular les estadístiques resum de la columna amb l’ajuda de
.agg() - Separar el conjunt de dades en grups amb l’ajuda de
.groupby()
Aquests mètodes de pandas poden ajudar-te a trobar valors atípics en les dades, avaluar una sèrie d’observacions i comparar grups amb la característica estadística desitjada.
No obstant això, tingues en compte el possible resultat quan realitzis una agregació i agrupació complicada de dades reals. Un diagrama dibuixat en paper pot estalviar hores de correcció de codi. Si continues obtenint errors i respostes incorrectes, probablement no tingui res a veure amb l’ús de Python — potser la teva lògica estigui fallant.
Creuament de dades amb DataFrames
Com ja sabeu, hi ha dues estructures de dades principals pandas: Series (unidimensional) i DataFrames (bidimensional).
Abans, vas aprendre a crear objectes dels dos tipus. També heu après que podeu transferir dades de diferents fitxers i taules a DataFrames.
Ara, imagineu-vos que heu de treballar amb diversos conjunts de dades similars o relacionats i processar-los de la mateixa manera.
Què és el primer que podríeu fer per facilitar aquesta tasca? Potser us agradaria combinar-los.
Per sort per a tu, pandas proposa diverses maneres de fer-ho. En aquest tema, aprendràs a unir-te DataFrame i Series objectes utilitzant funcions concat() i merge().
Referència:
- [https://medium.com/analytics-vidhya/python-tip-6-pandas-merge-dev-skrol-bf0be41f29b7]
Concaternació (concat)
La funció concat s’utilitza per concatenar o enganxar diversos objectes junts al llarg d’un eix horitzontal o vertical.
Per fer-ho, hem de passar múltiples Series o DataFrames com a arguments de la funció.
Però primer, crearem dos DataFrame: les taules que emmagatzemen els noms dels estudiants i els seus resultats després d’una competició d’atletisme en proves de 100 metres i 2 quilòmetres respectivament:
= : ,
: },
=)
= : ,
: })Tingueu en compte que els seus índexs són diferents i independents entre si: el primer DataFrame està indexat en el rang 1-4 i el segon té el valor predeterminat 0, 1, 2, … .
Es fa amb finalitats il·lustratives: la indexació és important en la concatenació, així que mostrarem com aquestes diferències afecten els resultats i com es poden restablir els valors inicials.
Ara, hauríem de passar el DataFrames a concat() com a seqüència o mapeig:
) )
Com heu pogut notar, el segon DataFrame s’ha afegit a sobre del primer.
Què passa si els vols afegir un al costat de l’altre?
Tot i que té sentit quan es tracta d’índexs significatius (per exemple, anys, dni, cognoms), en el nostre cas probablement ens agradaria tornar-los a calcular.
Aquests i alguns altres problemes es poden resoldre ajustant els paràmetres següents:
axis — l’eix al llarg del qual s’ha de concatenar. Els valors possibles són 0 i 1 (‘0’ per defecte): axis=0 significa combinar al llarg de les files, i axis=1 és per combinar al llarg de columnes. Ara establim el valor de axis a 1:
) ) ) )
Us heu adonat que alguns camps estan plens de valors de NaN?
NaN significa “No és un número”.
Aquesta és la manera de gestionar els valors que falten pandas i a Numpy; ho hem vist a:
Com ja hem vist, junior_class i senior_class estan indexats de manera diferent.
Per tant, cada vegada que hi hagi aquests desajustos, els camps de dades no coincidents s’ompliran de NaN.
ignore_index— mantenir o restablir els índexs originals en concatenar. Els valors possibles són “True” i “False” (per defecte “False”).
Si voleu que el vostre objecte resultant es torni a ordenar, especifiqueu-lo ignore_index=True.
Ara, l’eix s’etiquetarà amb índexs numèrics que comencen per 0:
) )
Si li afegim un tercer dataframe també ens el fa bé:
= : ,
: })
= join — combinant-se amb el ’ exterior ’ o ’ interior tipus d’unió ’ (‘exterior’ per defecte). El tipus d’unió exterior retorna la unió de tots els objectes, és a dir, es conservaran totes les seves files originals. Per contra, el tipus intern inclou només les files etiquetades amb índexs presents als dos conjunts de dades, excloent totes les altres files.
Mireu l’exemple següent: hi ha files marcades amb els números 1, 2 i 3, però les files marcades amb 0 (de senior_class) i 4 (des de junior_class) s’eliminen:
) ) ) )
keys— afegir un nou nivell d’etiquetes per indicar, per exemple, de quines Series o DataFrame els valors provenen o els agrupa d’una altra manera.
Els noms s’han de passar com una seqüència, per exemple, llista:
) )
Fusió (merge)
Comparat amb concat(), merge()és una eina de combinació més flexible que ofereix possibilitats d’aprofundir una mica més en l’estructura dels objectes. La funció està arrelada en la idea de l’anomenada unió a l’estil de base de dades : unir-se a partir de columnes compartides.
Si esteu familiaritzat amb els tipus d’unions SQL i SQL, la funcionalitat principal de merge() us recordarà les operacions següents: INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN i FULL OUTER JOIN.
TODO “pd_join.png” (no està imatge)
La funció necessita dos objectes per operar:
Un DataFrame per una banda; i un altre DataFrame o una Series.
Farem servir el DataFrame cap a junior_class de l’apartat anterior.
Suposem que volem fusionar-lo amb un de nou DataFrame que conté informació sobre l’edat dels participants.
Suposem que inclourem només tres membres al dataframe:
= : })Ara, passem els dos DataFrame objectes a merge():
) )
Com podeu veure, només tenim dues files. Tots dos junior_class i age_of_participants tenen la mateixa columna “Nom”.
Així, per defecte, s’uneixen a partir d’aquesta clau coincident.
Només les files que tenen valors superposats de “Nom” en ambdues DataFrames es produeixen: la informació sobre l’edat dels altres participants no està disponible i tindran NaN contra els seus noms a la columna “Edat”, de manera que els seus resultats no s’inclouen a la taula final.
Això passa perquè merge() té un paràmetre semblant a join de concat(), i s’estableix per defecte al tipus d’unió interior. Vegem algunes altres opcions i paràmetres per ajustar els resultats:
how- defineix la manera de fusionar. Els valors possibles són ìnner, outer, left i right per defecte inner.
A dalt, vam veure un exemple de combinació interior; si especifiquem ‘exterior’, obtindríem la unió de totes les dades.
A veure què passa si escrivim how=‘left’:
) )
Podem veure totes les entrades del primer conjunt de dades, tot i que alguns valors de la columna “Edat” estan absents. De la mateixa manera, how=‘right’ ens aconseguirà totes les files del segon DataFrame.
Per exemple, la fila, corresponent al nom ‘Ella’, té valors de NaN en ‘100m (seg.)’ i ‘2km (min., seg.)’, ja que junior_class no conté informació sobre les seves puntuacions:
) )
on- permet combinar dos dataframes basant-se en una o més columnes que comparteixen alguna relació.
left_on** i right_on s’utilitzen per especificar les columnes en les quals vols basar la unió dels dos dataframes.
La diferència principal entre els dos és:
left_on: Especifica la columna (o columnes) del dataframe de l’esquerra (el primer dataframe) que utilitzaràs per fer la unió.right_on: Especifica la columna (o columnes) del dataframe de la dreta (el segon dataframe) que utilitzaràs per fer la unió.
Exemple Pràctic funció merge amb paràmetre on
Imagina que tens dos dataframes: df1 i df2; que volem unir utilitzant les columnes id de df1 i identificador de df2.
# Dataframes d'exemple
= : ,
: ,
:
})
= : ,
: ,
:
})
=
Resultat:
| | | | | | |
|||||||
| | | | | | |
| | | | | | |Amb aquests paràmetres, pots unir dataframes fins i tot si les columnes que utilitzes per unir-los tenen noms diferents en cada dataframe.
Diferències entre concat i merge.
Ara que hem revisat els casos d’ús d’ambdues funcions, aclarim les diferències clau entre elles:
- Principals casos d’ús. En general,
concat()s’utilitza simplement per col·locar diversos objectes un al costat de l’altre o un sobre un altre; al mateix temps, merge()s’utilitza principalment per unir-se com a base de dades: el seu conjunt de paràmetres fa que la unió sigui més flexible i més conscient del contingut. - El nombre d’objectes que podem unir.
concat()pot acceptar una seqüència de diversos objectes, mentremerge()només ens permet unir-ne dos DataFrames o a DataFrame i un nom Series. - Tractament d’eixos (axis). Quan s’utilitza
concat(), podeu especificar l’eix al llarg del qual necessiteu unir objectes;merge()només admet la unió una al costat de l’altra. - Operacions semblants a bases de dades.
concat()només pot realitzar una unió interna o externa, mentremerge()pot fer tipus d’unió interior, exterior, esquerra i dreta.
Exercicis.
Fusiona els 3 dataframe de dades mèdiques amb informació addicional sobre els pacients utilitzant la columna “Pacient” com a clau de fusió. Assegura’t que no apareguin files duplicades i que tota la informació existeix.
= : ,
: ,
:
}
=
= : ,
:
}
=
= : ,
:
}
= Sortida esperada:
{% sol %}
Fusiona els tres DataFrames utilitzant “Pacient” com a clau i amb l’opció “how=‘outer’” per assegurar que tots els pacients estiguin presents.
=
=
Fixeu-vos que amb el concat no és suficient, per molt que li fiquem outer. Per a què el concat funcionés bé totes les files haurien de ser comunes.
Concaterna els tres DataFrames utilitzant “Pacient” com a clau
= ], =1, =True, =)
{% endsol %}
Exemple: fusionar diversos fitxers csv comprimits.
Imagineu-vos que sou un científic de dades i que actualment esteu treballant amb les dades dels hospitals locals.
Tens diversos fitxers amb informació sobre pacients de diferents districtes. De vegades, les dades es divideixen en molts conjunts de dades o poden contenir valors buits o no vàlids.
El primer pas és preprocessar les dades abans de l’anàlisi: combinar els fitxers en un de sol, eliminar files buides o incorrectes, omplir els valors que falten, etc.
En aquesta etapa, tractaràs conjunts de dades que contenen informació sobre pacients de tres hospitals: un general, un prenatal i un altre esportiu.
Aquestes estan en un fitxer zip que conté 3 fitxers csv; anem a resoldre el repte!
: =
: =
=
= ,
)
=
=
=
# print(general.columns)
=
# print(prenatal.columns)
=
# print(sports.columns)
=
=
# Esborrem files que tinguin tot NaN.
# Ara, substituïm els valors de gender per a què només siguin m o f.
# Els Nan de gender de prenatal ens han dit de reemplaçar-los per f.
=
# Substituïm valors NaN a les columnes bmi, diagnosis, blood_test, ecg, ultrasound, mri, xray, children, months amb zeros
# La desviació que notem és que la alçada dels pacients de l’hospital d’Sports no s’ha mesurat en cm sinó en peus (1 peu = 30,48 cm aprox)
= ==
*= 0.3048
Resultat:
)
# Column Non-Null Count Dtype
))
Camps calculats.
Crear noves columnes que necessitem en funció d’altres és molt senzill!
Exemples on ens pot interessar:
- Tenim un camp edat i ens interessa separar per grups d’edat, per a poder fer recomptes i gràfics.
- Volem juntar nom i cognoms en un mateix camp.
- Volem calcular l’edat a partir de la data de naixement.
- Volem calcular l’imc a partir de l’alçada i el pes
- Volem extreure informació d’un camp string que conté informació rellevant; per exemple ens interessa el primer digit del codi dels ous.
Com crear un nou camp:
Facilissim, si usem el següent dataframe d’exemple:
= : ,
: ,
: ,
:
}
= Podem aconseguir un nou camp que es digui full_name amb el cognom i el nom; de la següent manera:
= + + Sortida:
O bé aconseguir un camp birth_year a partir del birthday:
= .
=
Crear un nou camp calculat amb apply:
Això ho aconseguim amb la funció apply. A aquesta li podem passar una funció lambda o una funció pura per a què la apliqui en cada fila (com feiem amb la funció map de Python).
Provem un parell d’exemples amb dades de pacients generades aleatòriament:
: = 20
: = 120
= 1.20
= 2.20
: = 40
: = 140
= : ,
: ,
:
})
Exemple 1. Nou camp imc (bim).
El calculem amb la formula
pes (kgs.) / altura (cms.) ^2
return axis=1, apliquem resultats a les columnes.
= Exemple 2. Nou camp que defineix si un pacient és major a 65 o menor.
return
=
Amb funcions lambda:
= Sortida:
Fixeu-vos que ha creat correctament els 2 camps.
Exemple 3. Classificació de grups d’edat més avançada:
= : ,
:
}
= Solució
return
return
return
return
return
return =
Sortida:
Si tenim molts intervals d’edat val la pena usar la funció cut i llistes:
Defineix els intervals d’edat i les etiquetes dels grups
=
= Utilitza la funció ‘cut’ per classificar les edats als grups:
= Codi de l’exemple 3 (les 2 funcions):
= : ,
:
}
=
#Defineix els intervals d'edat i les etiquetes dels grups
=
=
# Utilitza la funció 'cut' per classificar les edats als grups
=
Podem constatar que s’ha realitzat la agrupació correctament:
Despres d’agrupar les dades, podem obtenir informació valuosa:
# Número de pacients per gènere.
Exemple 4. Agafar una data i extreure’n informació:
Fixeu-vos en aquest exemple, en el que a partir d’una data de naixement agafem només l’any i després calculem la data.
Fixeu-vos que cal garantir que la data sigui format datetime.
= : ,
:
}
=
=
= ..
= .
= -
Sortida:
També funciona per formats de data com el nostre (dd/mm/yyyy)
= : ,
:
}
0 1990-05-15 1990 33
1 1985-10-20 1985 38Projecte REST
1.- En base al projecte https://gitlab.com/xtec/python/pandas que gestiona diversa informació sobre vols al món.
-
Mostra tots els vols d’un any concret en un endpoint (arrenca l’exemple)
-
Crea un enpoint que mostri totes les dades d’un registre per index (l’index serà un valor autonumèric).
-
Crea un o dos endpoints més que filtrin altres dades: ciutat origen/destí, etc…
-
Crea enpoints RESTful a inserir (POST), actualitzar (PUT) o eliminar (DELETE) un registre del dataframe de vols.
-
Mostra un gràfic d’algunes columnes dataframe a la web, de dades agrupades.
2.- Crear un servidor d’un Hospital que permeti a aplicacions client consumir les dades de l’hospital tal com s’explica a {% link “/python/fastapi/rest/” %}
Crea almenys un mètode tipus GET:
-
Un que retorni un dataframe de dades públiques d’un hospital en format JSON (no totes les del dataframe)
-
Si et sobra temps, que mostri un gràfic amb informació pública (això ho veurem a la propera sessió)
-
A la pròxima sessió també veuràs com posar més funcionalitats.
Pista 1: Aquí teniu com retornar el dataframe del titanic que ve per defecte amb la llibreria Seaborn.
=
=
return