Nucleic acid
DNA is the genetic material of living organisms
Introduction
Nucleic acids are organic biomolecules responsible for storing and disseminating genetic information. There are two fundamental types of nucleic acids, deoxyribonucleic acid (DNA), and ribonucleic acid (RNA).
Nucleic acids are macromolecules composed of units called nucleotides.
There are two types: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA).
DNA
DNA is the genetic material of living organisms, from single-celled bacteria to multicellular mammals like you and me.
Some viruses use RNA as their genetic material, but they are not considered living beings, since they cannot reproduce without the help of a host.
DNA is divided into chromosomes, and each chromosome can contain tens of thousands of genes.
In prokaryotic organisms, such as bacteria, DNA is found in a specialized region of the cell called the nucleoid, and the chromosomes are much smaller and often circular (ring-shaped).
In eukaryotic cells, such as those of plants and animals, DNA is found in the nucleus, a specialized membrane-enclosed chamber within the cell, as well as in certain different types of organelles (such as mitochondria and plant chloroplasts).
Gene
Even though DNA is enormous, only a part of it is coding, and one of the challenges of bioinformaticians is to discover those segments of DNA that provide instructions on how to make a particular product that the cell needs.
DNA is not used directly; instead, copies of the part that codes for the gene are made in RNA whenever needed.
Many genes indicate the sequence of amino acids used to synthesize a protein in a ribosome by means of messenger RNA (mRNA).
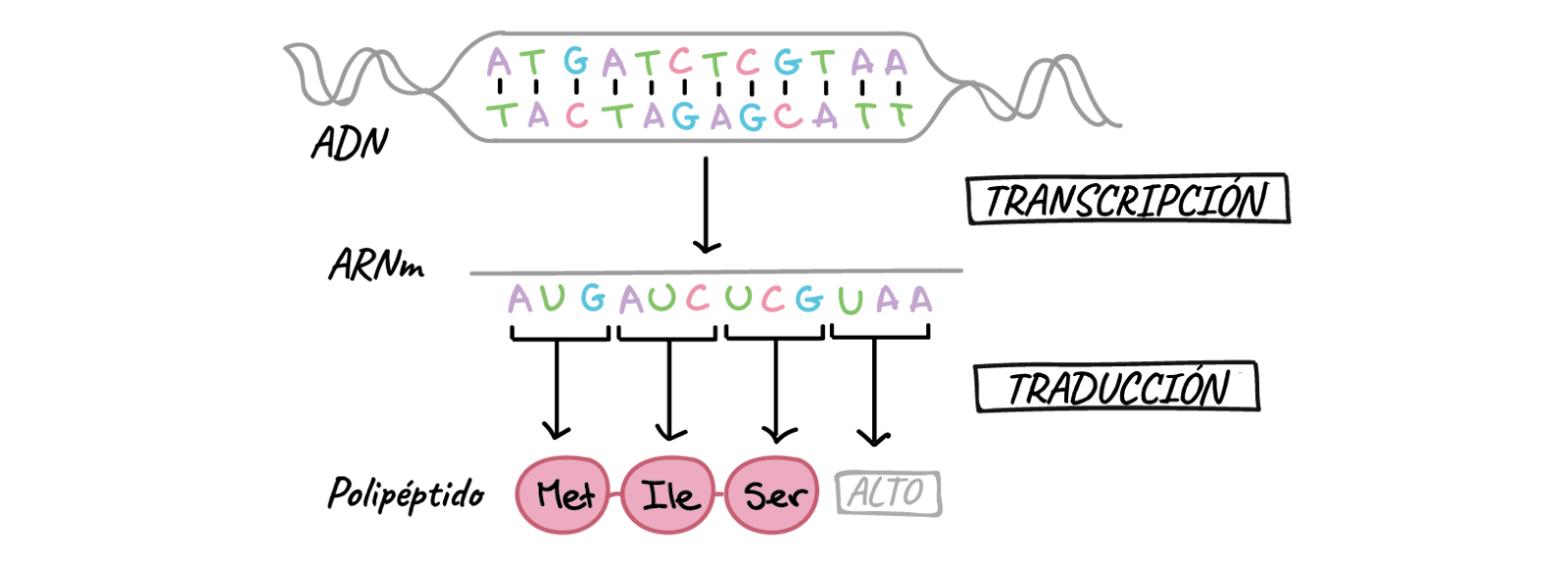
As we said before, not all genes code for protein products.
Below are some examples of different types of RNA:
-
Ribosomal RNA (rRNA): Serves as a structural component of ribosomes
-
Transfer RNA (tRNA). These are clover-shaped RNA molecules that carry amino acids to the ribosome for protein synthesis.
-
Micro RNA (known as miRNA). They act as regulators of other genes.
Nucleotides
DNA and RNA are polymers (in the case of DNA they are usually very long polymers) and are made up of monomers known as nucleotides (A, C, G…). When these monomers combine, the resulting chain is called a polynucleotide (poly- = “many”).
Each nucleotide is made up of three parts:
- A five-carbon sugar that has a central position.
- A nitrogen-containing ring structure called a nitrogenous base.
- At least one phosphate group.
The sugar molecule has a central position in the nucleotide, the base connects to one of its carbons and the phosphate group (or groups) to another. Let’s look at each part of a nucleotide one at a time.
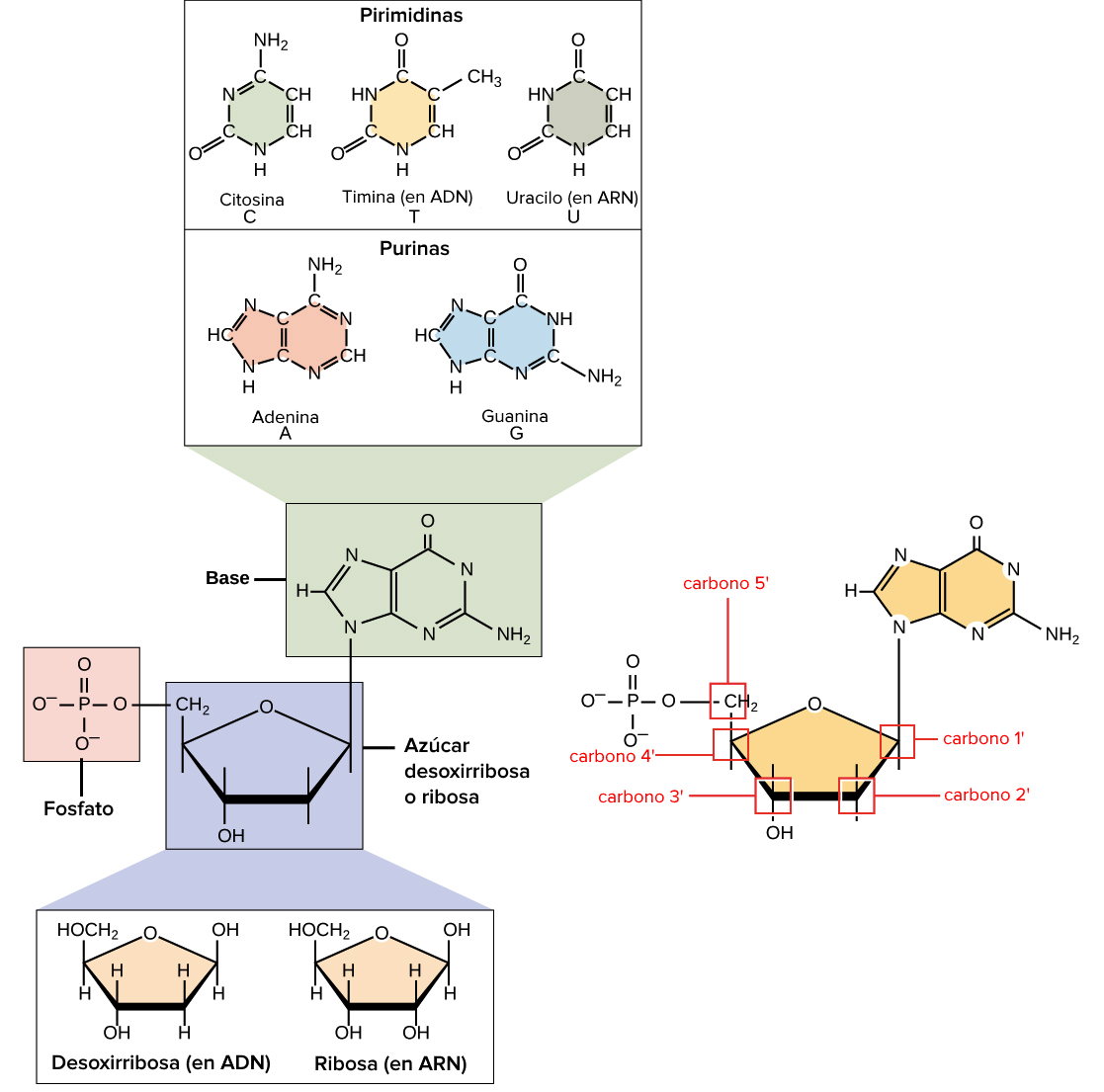
Image of the components of DNA and RNA, which include the sugar (deoxyribose or ribose), the phosphate group, and the nitrogenous base. The bases comprise the pyrimidine bases that have one ring (cytosine and thymine in DNA, and uracil in RNA) and the purine bases with two rings (adenine and guanine). The phosphate group attaches to the 5’ carbon. The 2’ carbon has a hydroxyl group in ribose, but only hydrogen (not hydroxyl) in deoxyribose.
Nitrogenous bases
The nitrogenous bases of nucleotides are organic (carbon-based) molecules, composed of ring structures that contain nitrogen. Why are they called bases? Since some of the nitrogens in the base can become protonated (receive an H+ ion), nitrogenous bases decrease the concentration of hydrogen ions in a solution and are therefore bases in the acid-base sense.
Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G), cytosine (C) and thymine (T).
Adenine and guanine are purines, which means that their structures contain two fused rings of carbon and nitrogen.
In contrast, cytosine and thymine are pyrimidines and have only one ring of carbon and nitrogen.
RNA nucleotides can also contain adenine, guanine and cytosine bases, but they have another pyrimidine-type base called uracil (U) instead of thymine. As shown in the previous figure, each base has a unique structure, with its set of functional groups attached to the ring structure.
As abbreviations in molecular biology, nitrogenous bases are usually named by their single-letter symbols: A, T, G, C and U.
DNA contains A, T, G and C, while RNA contains A, U, G and C (that is, U is swapped for T).
The sugars
In addition to having slightly different sets of bases, DNA and RNA nucleotides also have slightly different sugars. The five-carbon sugar of DNA is called deoxyribose, while in RNA the sugar is ribose. These two molecules are similar in structure, with only one difference: the second carbon of ribose has a hydroxyl group, while the equivalent carbon in deoxyribose has a hydrogen in its place.
The carbon atoms of a sugar molecule are numbered 1’, 2’, 3’, 4’ and 5’ (1’ is read “one prime”), as shown in the previous figure.
In a nucleotide, the sugar occupies the central position, the base attaches to the 1’ carbon and the phosphate group (or groups) attaches to the 5’ carbon.
The phosphate
Nucleotides can have either a single phosphate group or a chain of up to three phosphate groups attached to the 5’ carbon of the sugar. Some chemical information sources use the term “nucleotide” only for the single-phosphate case, but in molecular biology the broader definition is generally accepted.
In a cell, the nucleotide to be added to the end of a polynucleotide chain will contain a series of three phosphate groups. When the nucleotide joins the growing DNA or RNA chain it loses two phosphate groups. Therefore, in a DNA or RNA chain, each nucleotide has only one phosphate group.
Polynucleotide chains
A consequence of the structure of nucleotides is that a polynucleotide chain has directionality, that is, it has two ends that are different from each other.
At the 5’ end, or start of the chain, the phosphate group attached to the 5’ carbon of the first nucleotide protrudes. At the other end, called the 3’ end, the hydroxyl attached to the 3’ carbon of the last nucleotide is exposed.
DNA sequences are generally written in the 5’ to 3’ direction, which means that the nucleotide at the 5’ end is the first and the nucleotide at the 3’ end is the last.
As new nucleotides are added to a DNA or RNA chain, it grows at the 3’ end, when the 5′ phosphate of the incoming nucleotide joins the hydroxyl group at the 3’ end of the chain. This produces a chain where each sugar is joined to its neighbors by a series of bonds called phosphodiester bonds.
Characteristics of DNA
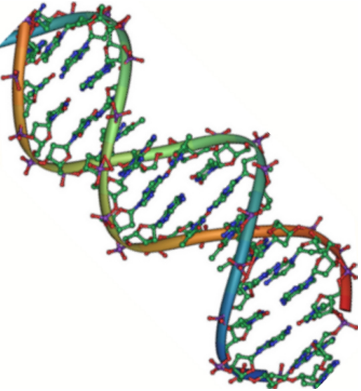
In deoxyribonucleic acid, or DNA, the strands are normally found in a double helix, a structure in which two paired (complementary) strands join together, as shown in the diagram.
The two strands of the helix run in opposite directions, which means that the 5′ end of one strand joins the 3′ end of its corresponding strand. This is known as antiparallel orientation and is important when replicating DNA.
So, can any two bases decide to join and form a pair in the double helix? The answer is a definite no. Because of the sizes and functional groups of the bases, base pairing is extremely specific: A can only join with T and G can only join with C, as shown below.
For example, if you know that the sequence of one strand is 5'-AATTGGCC-3', the complementary strand must have the sequence 3'-TTAACCGG-5'.
This allows each base to join with its pair: A-T pairs are joined by two hydrogen bonds and G-C pairs by three.
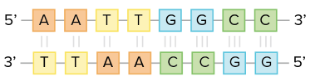
It is said that two DNA sequences are complementary when their bases can pair and join with each other in an antiparallel way, forming a helix.
DNA strands join in a double helix of antiparallel strands by means of hydrogen bonds between the complementary bases. Thymine forms two hydrogen bonds with adenine and guanine forms three hydrogen bonds with cytosine.
DNA replication.
DNA replication is the process by which two identical copies are produced from an original DNA molecule. Replication takes place in all living organisms and is the biological basis of inheritance, that is, it is the molecule that will be transmitted to offspring.
During DNA replication, the double helix splits into two parts: the nitrogenous bases of each half pair up with the homologous base, thus forming the missing strand. This means that each of the original strands will serve as a template for the synthesis of a new strand.
This fact ensures high fidelity in replication, as well as facilitating the correction of errors that may occur during replication.
A mutation is an error in base pairing. For example, in the sequence AATTGGCC, a mutation can cause the second T to change to a G. Most of the time when this happens DNA is able to fix itself and return the original base to the sequence.
However, sometimes the repair is not successful, which results in the creation of different proteins.
Characteristics of RNA
-
Structure of RNA:
- RNA is single-stranded with ribose as its sugar.
- It has nitrogenous bases
A,U,G,C.
-
Types of RNA:
- Messenger RNA (mRNA):
- Serves as an intermediary between a gene and its protein.
- It is transcribed from
DNAby substitutingTwithU. - mRNA interacts with the ribosome to synthesize proteins from codons (groups of three nucleotides).
- Ribosomal RNA (rRNA):
- Essential component of ribosomes.
- It can act as an enzyme (ribozyme), catalyzing the joining of amino acids into proteins.
- Transfer RNA (tRNA):
- It carries amino acids to the ribosome according to the sequence of the
mRNA. - It has a complex three-dimensional structure for its function.
- It carries amino acids to the ribosome according to the sequence of the
- Regulatory RNA:
- Includes miRNA and siRNA, which regulate gene expression.
- They bind to the
mRNAto reduce its translation or stability. - They may be related to diseases such as cancer.
- Messenger RNA (mRNA):
There is increasing evidence that miRNAs and other small, non-coding RNAs participate in certain human diseases, such as in some genetic disorders and types of cancer.
In addition, researchers are developing artificial microRNAs that serve as therapeutic tools in the treatment of human diseases.
These are just a few examples of regulatory RNAs. There are many others and, over time, more continue to be discovered.
Applications and Perspectives
- Knowledge of the different types of RNA is advancing, with the discovery of new types such as lncRNA and piRNA.
- Artificial microRNAs are being developed for the treatment of genetic disorders and cancers.
This summary synthesizes the main points and makes it easier to understand the topic! 😊
Biopython Activity
Introduction
The Biopython project is an open-source collection of non-commercial Python tools for computational biology and bioinformatics, possibly the most recognized one in Python. It was created by an international association of developers.
It contains classes to represent biological sequences and sequence annotations, and is able to read and write in a variety of file formats. It also allows a programmatic means of accessing online databases of biological information, such as those of NCBI.
Separate modules extend Biopython’s capabilities to sequence alignment, BLAST, protein structure, population genetics, phylogenetics, sequence motifs, and machine learning.
The official documentation for the most recent version of Biopython can be found at:
API Biopython, lastest version
Installation
To speed up the session, clone the git repository that we have prepared and follow the instructions in the readme.md
In case you want to install and use Biopython in an existing Python and Poetry project use the command:
If you want, you can review how the Poetry package and environment manager works:
Seq
The Seq object is Biopython’s mechanism for handling sequences, which are essentially “strings” of letters like AGTACACTGGT.
The most important difference between Seq objects and standard Python strings is that they have different methods.
Although the Seq object supports many of the same methods as a simple string, the translate() method of Seq is different because it performs a biological translation, and there are also additional biologically relevant methods such as reverse_complement().
Create a file app/sequence.py.
In many ways we can treat Seq objects as if they were normal Python “strings”, for example, getting the length or iterating over the elements:
=
The result obtained is:
Estás leyendo una vista previa.
Inicia sesión para leer el artículo completo. Cualquier cuenta abre 4 artículos gratuitos al mes; el alumnado y el profesorado leen las páginas de su curso sin límite.
Iniciar sesión