Machine Learning
This activity reviews the machine learning algorithms commonly used for classification, which will be used with the bioactivity data stored in PubChem to build a predictive model of small molecule bioactivity
Machine Learning
Prior concepts about Artificial Intelligence
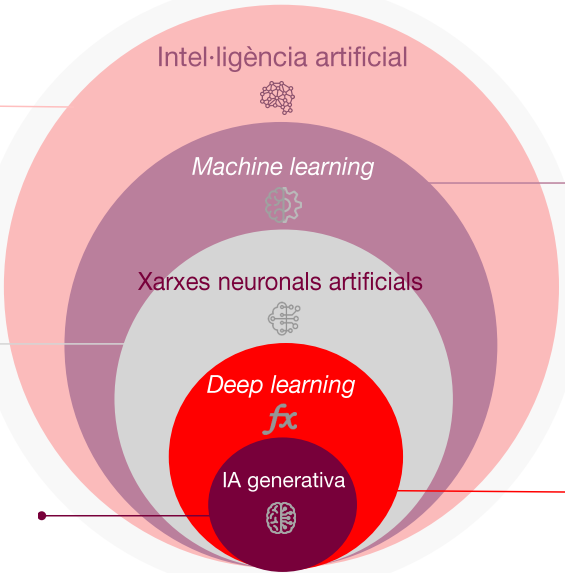
Artificial intelligence (AI) is a discipline that combines computing, data processing and automatic knowledge management to solve complex problems with minimal human intervention. It attempts to simulate different human behaviours through machines.
As you can guess, AI enables many new possibilities compared to “traditional” programming which, very briefly, only has the purposes of: reading, manipulating and representing information, solving specific problems, automating repetitive tasks or achieving specific results.
Machine learning is a branch of artificial intelligence that focuses on data-intensive processing algorithms to learn complex patterns of reality that allow it to be modelled. Some can gradually improve their accuracy as they process more data.
Artificial neural networks are a subset of machine learning and are at the heart of deep learning algorithms. Both the name and the structure are inspired by the human brain, mimicking the way biological neurons communicate with each other. Artificial neural networks must be trained with datasets in order to learn and can improve their accuracy as they process more data.
Deep learning is a type of artificial neural network that uses more complex operators and makes it possible to solve more complex problems with greater quality and less computation time.
Generative AI refers to deep learning models that, from raw data, can “learn” to generate more plausible results for each query, whether they are texts, images, video, code, music or other content.
In this tutorial we will focus on machine learning.
Introduction to machine learning.
Machine learning is an application of artificial intelligence (AI) that gives computer systems the ability to learn automatically from data, identify patterns and make predictions or decisions with minimal human intervention.
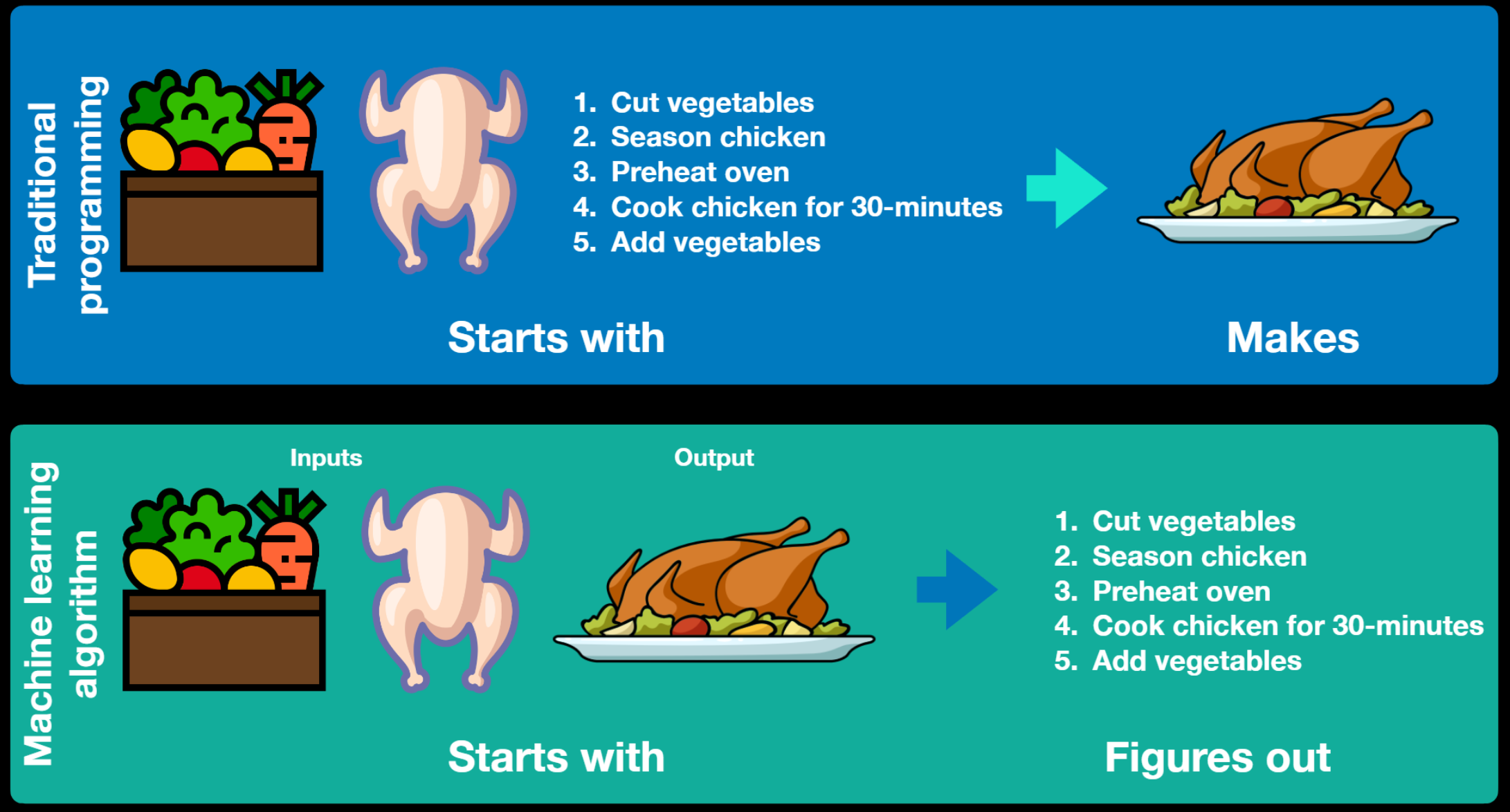
It focuses on the development of computational models that perform a specific task without using explicit instructions (as is done in traditional software programming)
Machine learning algorithms are used today in a wide variety of applications in many areas. This chapter reviews the machine learning algorithms commonly used for classification, which will be used with the bioactivity data archived in PubChem to build a predictive model of the bioactivity of small molecules for the task (link to the notebook from lecture 8).
There are several articles that provide comprehensive reviews on the application of machine learning in drug discovery and development, including the following documents:
Main categories of machine learning techniques (to be reviewed):
Supervised learning
In supervised learning, a model is built from a training dataset, which consists of a set of input data (represented with “descriptors” or “features”) and their known outputs (also called “labels” or “targets”).
This model is used to predict an output for new input data (not included in the training dataset). In short, supervised learning consists of building a model, y=f(X), that predicts the value of y from the input variables (X). [Note that X is capitalised to reflect that the input data is normally represented with a “vector” of multiple descriptors.]
An example of supervised learning is building a model that predicts the binding affinity of small molecules against a given protein based on their molecular structures represented with molecular fingerprints. [Here, the molecular fingerprints correspond to the input and the binding affinity corresponds to the output.]
Supervised learning algorithms can be divided into two categories (regression algorithms and classification algorithms), depending on the type of output data that the supervised learning aims to predict.
Regression
Regression algorithms aim to build a mapping function from the input variables (X) to the numerical or continuous output variable (y). The output variable can be an integer or a floating-point value and usually represents a quantity, size or force.
An example of regression problems is predicting the IC50 value of a compound against a target protein from its molecular structure, in order to measure the effectiveness of a substance in inhibiting a specific biological process (e.g. a disease)
A more general example would be predicting the course of a disease (for example the stages of cancer) and adjusting preventive treatments.
Classification
Classification algorithms attempt to predict the “categorical” variable from the input variables.
An example of classification problems is predicting whether a compound is agonist, antagonist or inactive against a target protein.
More general examples of classification can be applied to grouping patients into risk groups for cardiovascular diseases based on medical history data, lifestyles, and biomarkers; or even in the classification of X-ray images to identify the presence of tumours, fractures or other anomalies.
Unsupervised learning
Unsupervised learning methods identify hidden patterns or intrinsic features in the input data (X) and use them to group the data.
Unlike supervised learning, unsupervised learning does not use labels assigned to the input training data [that is, there are no output/target/label values (y) associated with the input data]. Therefore, it can be used to analyse unlabelled data.
An example of the problems that unsupervised learning can handle is grouping a set of compounds into small clusters according to their structural similarity (calculated using molecular fingerprints) and identifying the structural features that characterise the individual clusters.
[For this task, the input data (X) are the molecular fingerprints of the compounds.]