CSV
Exercicis de realització i verificació de consultes amb tests a un fitxer CSV (Comma Separated Value) amb publicacions científiques (pel mòdul de bioinformàtica).
Com realitzar consultes a fitxers CSV en Python ?
Aquesta és una activitat per consolidar els aprenentatges de Python adquirits en estructures de control i de dades (i anteriors), en funcions, en tractament de fitxers i en testing per tal de realitzar consultes a un fitxer CSV amb informació útil per a realitzar investigació científica.
La Font de dades del CSV és el portal Scimago Journals
The SCImago Journal & Country Rank is a publicly available portal that includes the journals and country scientific indicators developed from the information contained in the Scopus® database. These indicators can be used to assess and analyze scientific domains. Journals can be compared or analysed separately. Country rankings may also be compared or analysed separately.
En altres paraules, és una organització que analitza mitjançant diverses mètriques la qualitat de les publicacions cientìfiques de diversos llocs del món: l’H-Index, el total absolut d’articles citats, documents publicats durant 1 i 3 anys…
I perquè volem extreure informació en un fitxer CSV (Comma Separated Values) en la informàtica ?
Doncs repassem els avantatges dels CSV:
- Són fitxers de text que tenen informació organitzada i separada habitualment per simbols com:
punt i coma, coma, tabulador,… - Això permet que siguin molt fàcils de llegir i escriure per a programadors, i que puguin ser tractats amb qualsevol llenguatge o fins i tot des del
terminal de Linux. - Suporten tot el ventall de caràcters
Unicodesi és necessari (multiidioma). - Molt bon rendiment.
- Es poden obrir fàcilment amb programes de
fulls de càlcul(recomanable Libre Office) per si algú menys experimentat en informàtic hi ha de treballar.
Hi ha variacions dels fitxers CSV. Per exemple, si en comptes d’estar separats per comes estan separats per tabuladors, s’anomenen TSV (Tab Separated Value).
–
Extracció dades actualitzades de Scimago.
Per a extreure la versió més recent del fitxer accedir a la consulteu la web de Scimago i seguim els següents passos:
- Seleccionem els articles de “Medicine” de l’any 2022.
- La resta de camps deixem els que indica per defecte.
- Finalment, pitgem a “Download Data”.
- Posem el fitxer csv dins la carpeta on crearem el projecte.
En aquesta captura teniu una mostra dels passos:
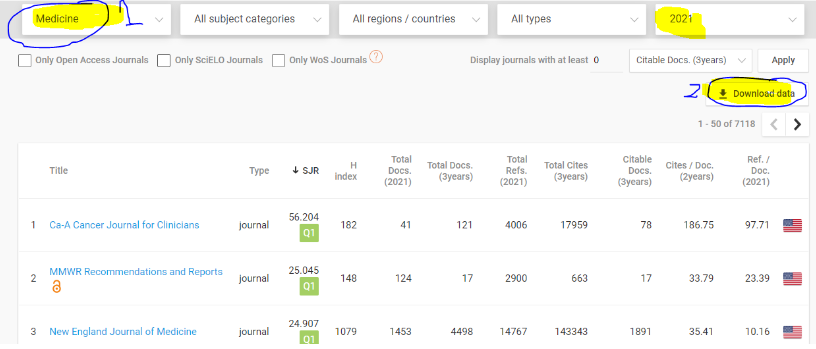
De tota manera, la versió que usarem per il·lustrar els tests és la del 2022 (més antiga). Si la voleu consultar n’hem guardat una còpia en un dels nostres projectes a Gitlab:
https://gitlab.com/xtec/bio/pandas/-/raw/main/data/scimago-medicine-2022.csv
Lectura del fitxer CSV.
Per llegir aquest fitxer en Python, utilitzarem una funció que li passarem la ruta i retornarà una llista amb totes les línies del fitxer.
Per facilitar la tasca usem la llibreria DictReader que crea el fitxer i el posa en un diccionari.
Cridarem aquesta funció i per provar que ha funcionat mostrem una línia. Només la primera perquè n’hi ha unes 7000 i pot tardar força en mostrar-les per pantalla!
# How to define a function in python with the word key
# the type date after the : is only documentation for Python
=
=
return
: =
: =
: =
La resposta (pel fitxer de l’any 2022) és:
}
Crear i organitzar consultes.
Ens han demanat que realitzem diverses consultes al fitxer CSV. No només han de funcionar sinó que hem de separar el codi: el/s mètodes per la lectura de fitxers han d’estar en un mòdul apartat dels programes on fem consultes.
També hem de crear un programa per testejar que cada consulta funciona, que retorna els resultats que esperem en qualsevol cas.
Comencem amb aquestes 2 consultes; que ja tenim resoltes en el codi, i només hem d’organitzar-les.
- Q1. How many entries are in scimago-medicine.csv?
- Q2. Show the n first entries.
file_utils.py
# Imports
'''Input: The file contents as a single string.
: is .
# DictReader converts each row in csv_file in a dictionary.
# The dictionary keys are the column names.
=
=
return scimago_queries.py
# Our imports
# 3rd party imports
# File name and path.
: =
# -----------------------------------------------------------------------------
# Q1. How many entries are in scimago-medicine.csv?
# -----------------------------------------------------------------------------
'''Input: List of entries
: . : =
#print("First entry:")
#pprint.pp(entries[0])
return
# -----------------------------------------------------------------------------
# Q2. Show the n first entries.
# -----------------------------------------------------------------------------
'''Input: List of entries, number of first items.
: in . return
# Main
# -----------------------------------------------------------------------------
: =
: =
: =
# -----------------------------------------------------------------------------Ja funcionen, i la lògica de les consultes està totalment separada de la de lectura del fitxer.
–
Testejar consultes.
Ja tenim les consultes creades. Ara, crearem funcions per verificar automàticament que funcionen, és a dir tests.
Si no ho has fet encara, instal·la Pytest dins del teu projecte.
Si teniu problemes descobrint els tests amb el plugin de VSCode, esbborreu la carpeta .vscode i reinicieu el VSCode; tal i com explica la web oficial de VSCode:
[https://code.visualstudio.com/docs/python/testing]
Ara, ja podeu crear aquest programa amb els tests a les 2 queries. Segurament caldria afegir més tests per a la consulta 2 (més casos) però per ara servirà per executar correctament Pytest.
Recomanem usar aquesta estructura de fitxers/mòduls per tal de separar adequadament el codi:
Donarem per suposat que el fitxer CSV del 2022 ja l’hem descarregat, els 2 anteriors fitxers Python ja els hem creat anteriorment i a continuació crearem el fitxer que usarem per executar els tests:
scimago_tests.py
: =
: = 7125
assert ==
=
=
=
assert ==
assert == Com podeu veure, els mètodes de test passen les proves perquè retorna els valors que esperavem tenint en compte el fitxer CSV del 2022:
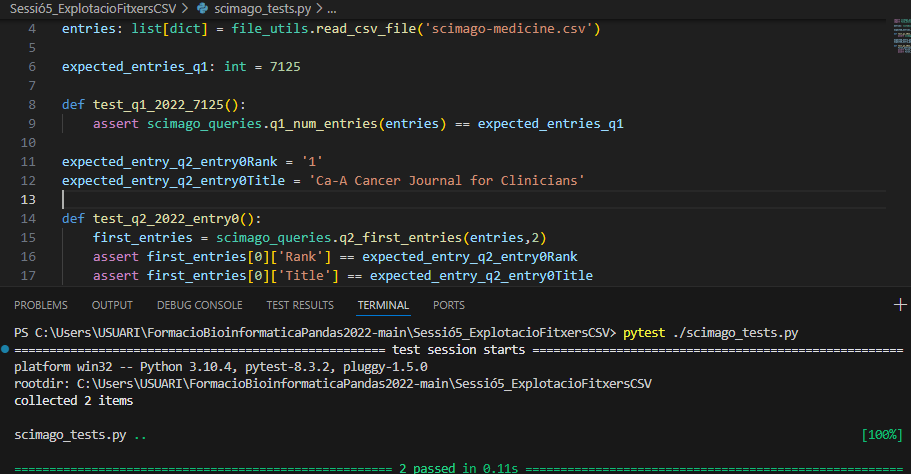
Exercici previ. Per assegurar-te que et funcionen els tests, crea un altre test per provar la segona consulta (q2). Aquest test ha de provar que el contingut del segon registre és el que esperem, contrastant el rank, el títol, l’H-Index, i el tipus de publicació
{% sol %}
=
=
=
=
=
assert ==
assert ==
assert ==
assert == {% endsol %}
Ara que ja sabem com crear i provar consultes; en realitzarem de més interessants.
–
EXERCICIS: Crear i provar consultes.
Prova de crear les consultes que plantegem a continuació (dins del scimago_queries.py) i de provar-les (dins del scimago_tests.py).
Valorarem positivament que insereixis mètodes comuns en diverses consultes a file_utils.py.
Moltes d’aquestes consultes tenen diverses solucions i és important que provis de resoldre-les pel teu compte i només mirar les solucions quan et quedis encallat.
I un cop contrastis la solució amb la que has obtingut tu, que entenguis com has arribat a la solució, i plantejar-te pel teu compte consultes similars.
Així és com es dominen les tècniques de Big Data que cada cop s’aplicaquen més freqüentment en el món laboral.
- ?
- in
- in ?
:
- .
- .
:
- -
- =.Possibles solucions consulta 3.
{% sol %}
Codi consulta 3.
#Solució 31, iterativa.
'''Input: List of entries, number of first items.
: in . : = 0
+=1
return
#Solució 32, funcional.
return ==
'''Input: List of entries, number of first items.
: in . return Test consulta 3.
: = 137
assert == {% endsol %}
Possibles solucions consulta 4.
{% sol %}
Codi consulta 4.
# -----------------------------------------------------------------------------
# Q4 - Show all the journals (Type = journal) published in UK
# (Country = United Kingdom) with an H-Index greater than 200,
# sorted by H-index (biggest H-Index first)
# -----------------------------------------------------------------------------
'''Input: List of entries.
: . : =
=
return
'''Input: List of entries.
: True return == and == \
and > 200 Test consulta 4.
=
=
=
assert ==
assert ==
= 55
=
assert == {% endsol %}
Possibles solucions consultes 5 i 6.
{% sol %}
Codi consultes 5 i 6.
# -----------------------------------------------------------------------------
# Q5 - What types of scientific publications are in the file (paràmetre Type)?
# -----------------------------------------------------------------------------
'''Input: List of entries.
: : =
return
# -----------------------------------------------------------------------------
# Q6 - Count the number of types of each scientific publication.
# -----------------------------------------------------------------------------
'''Input: List of entries.
: =
# if Type don't exist, we add it in the dict.
=1
# if Type exist, we sum 1 more publication.
= + 1
return Test consultes 5 i 6.
: = \
assert == )
# expected_result_q6: dict[str,int] = {'journal': 7082, 'book series': 27, 'conference and proceedings': 5, 'trade journal': 4}
: =
assert == . \
{% endsol %}
Podem trobar més solucions dins dels fitxers: